According to wikipedia, «in computer science, data validation is the process of ensuring that a program operates on clean, correct and useful data. It uses routines, often called validation rules or check routines, that check for correctness, meaningfulness, and security of data that are input to the system. The rules may be implemented through the automated facilities of a data dictionary, or by the inclusion of explicit application program validation logic ».
In other words, the data are checked against a data model. The data model could be simple or elaborated : it is up to the human validator to define to which extent the data have to be validated.
Often data validation is understood as validating numbers, dates and text, i.e. verifying types and ranges. For that purpose, spreadsheet dedicated function can do the job. However in a number of applications the data model could be quite complex and verification difficult to automate, hence leaving room for human errors during validation.
Example :
In the following spreadsheet, A,B,C and D are 4 natural numbers such as D is the sum of A,B and C.
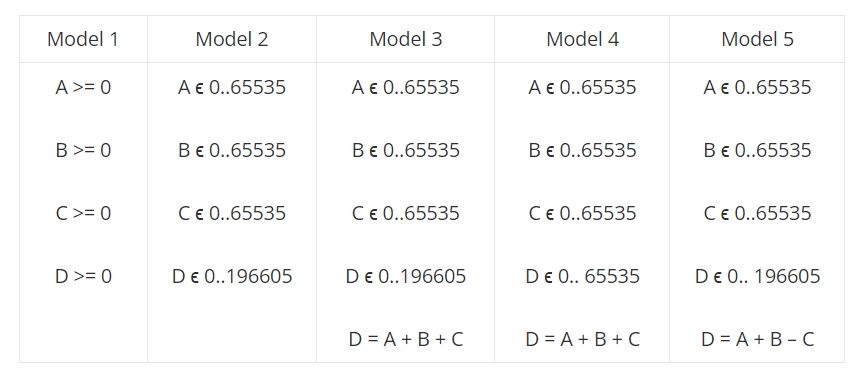
Models 1 to 3 are correct: every predicate appearing in the column is true. These models address diverse levels of verification, model 3 being the most complete / most constrained. With model 1, any tuple of natural numbers is acceptable. With model 3, only a finite set of tuples comply.
On the other hand, one could make mistakes in a data model, leading to situations where the model is partly correct.
In the previous table :
- model 4 is not verified if A+B+C >= 65536.
- model 5 is only verified when C = 0.
This example is very simple, however it shows that this kind of verification is tricky as data, model or both could be wrong. So a particular attention is to be paid to the following issues:
- how to detect wrong data ? Validation rules are the key. These rules, expressed using a mathematical language, allow for specifying data domain. Data that doesn’t fit with data domain are wrong. Comma.
- how to be sure that data tagged as “correct” is correct ? Human in the loop is a great source of errors (V&V is usually an activity boring as hell), especially when data set is huge and data model is complex. The way to go is to use tools that could be replayed at will . The ideal solution would be redundancy i.e. two independent tools drawing the same conclusion.
- to what extent is the model sound ? However we are not completely safe as we could made mistakes such as our faulty model complies with our faulty data (errare humanum est, persevare diabolicum). Another possibility is to have a data model “correct most of the time” (but incorrect on some cases that could not happen in a given data set but will surely happen later, thank to Murphy’s laws). Testing validation rules to ensure that wrong data are detected is to be envisaged but it doesn’t allow you to claim that your data are definitely validated as only partial test could be managed most of the time, data domain being too large.